เผยแพร่: 24 เมษายน 2569
สรุปสาระสำคัญ
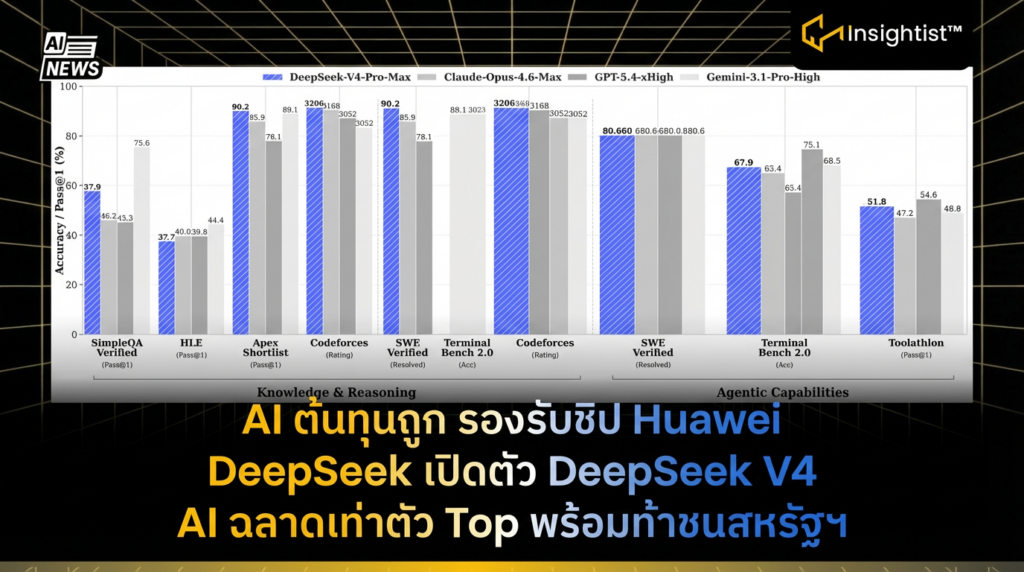
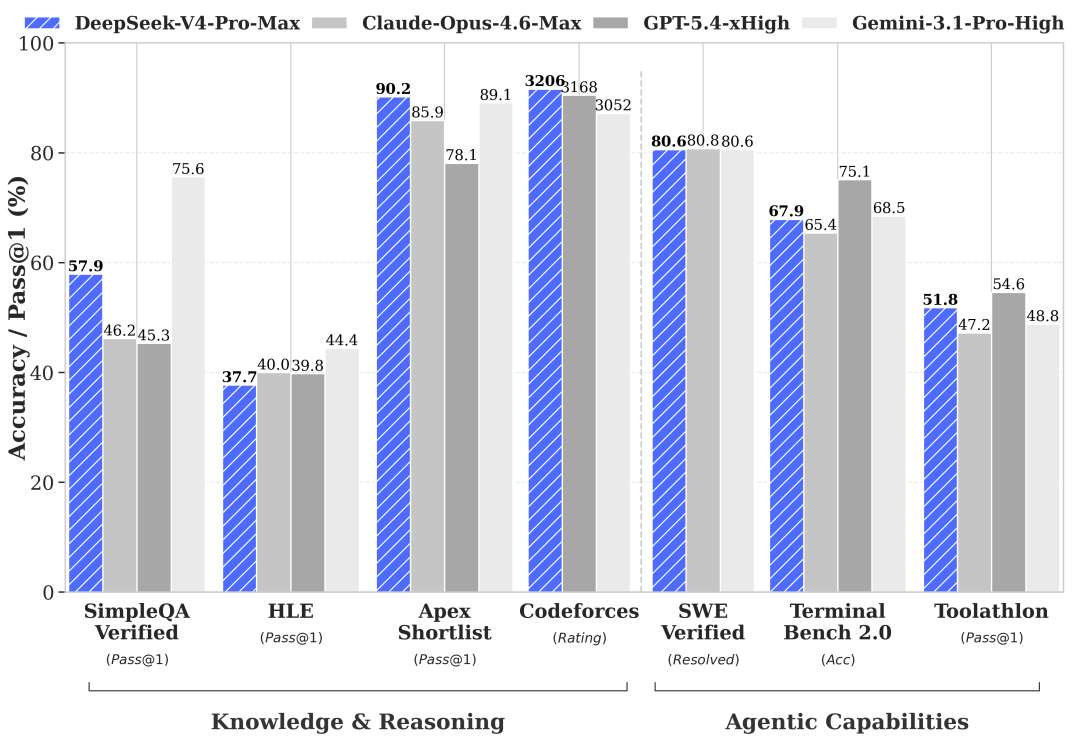
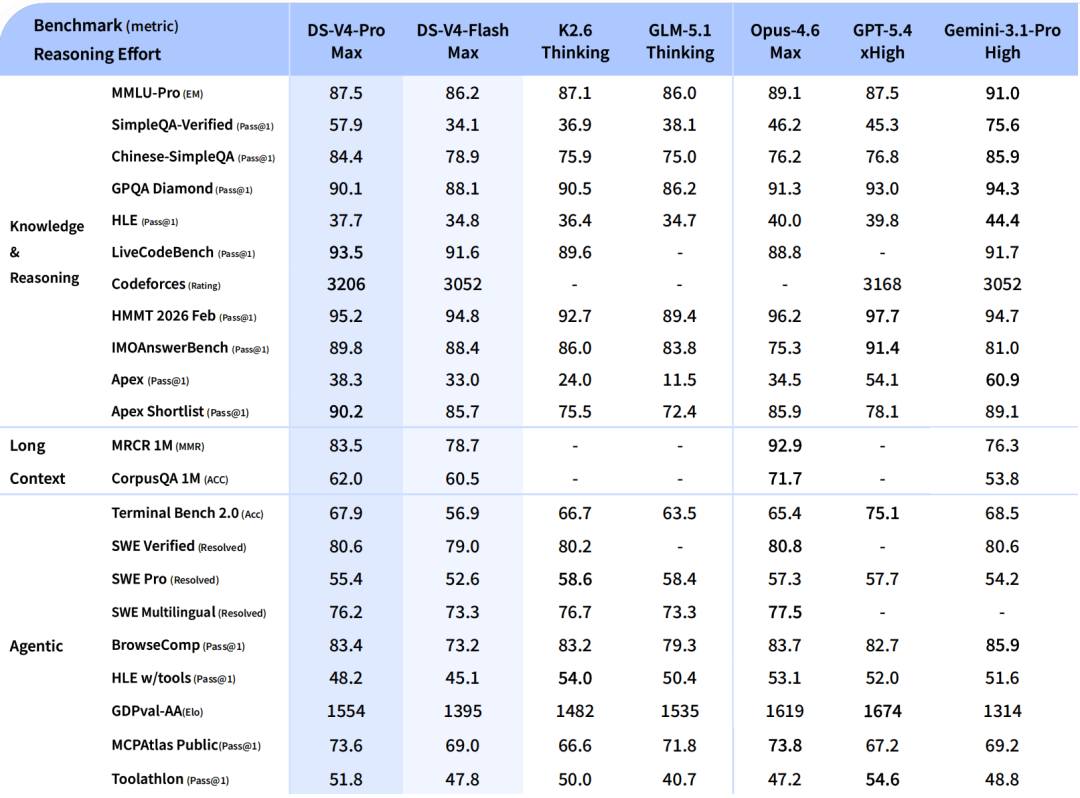
- DeepSeek เปิดตัวโมเดลใหม่ 2 รุ่นคือ V4-Pro (1.6T พารามิเตอร์) และ V4-Flash (284B พารามิเตอร์) ที่มีความสามารถเทียบเท่า AI ระดับท็อปจากสหรัฐฯ
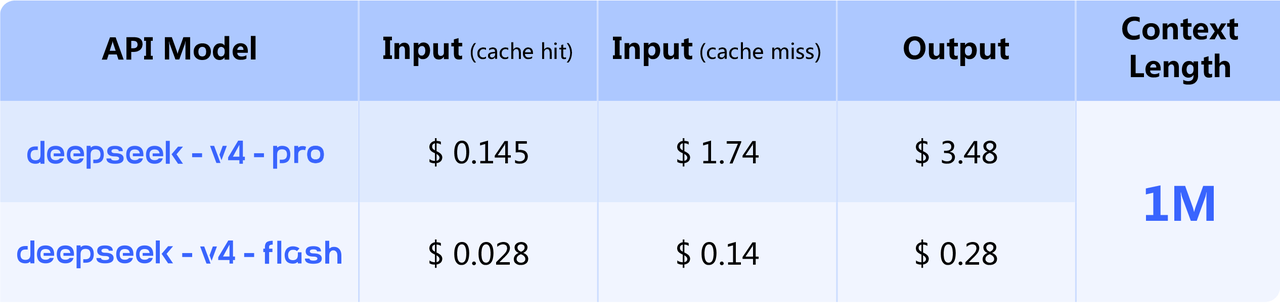
- ราคา API ถูกลงอย่างมีนัยสำคัญ พร้อมรองรับการประมวลผลข้อมูลยาวระดับ 1 ล้าน Tokens เป็นมาตรฐานทุกบริการ
- รองรับการทำงานร่วมกับ AI Agents ชั้นนำอย่าง Claude Code, OpenClaw และ OpenCode เพื่อขับเคลื่อนระบบอัตโนมัติในองค์กร
- โมเดลเดิมอย่าง deepseek-chat และ deepseek-reasoner จะยุติการให้บริการถาวรหลังวันที่ 24 กรกฎาคม 2569 เวลา 15.59 น.
DeepSeek V4 คืออะไร และทำไมธุรกิจควรติดตาม?
DeepSeek V4 คือตระกูลโมเดลภาษาขนาดใหญ่รุ่นใหม่จาก DeepSeek ที่ออกแบบมาเพื่อให้ประสิทธิภาพระดับสูงในต้นทุนที่เข้าถึงได้ โดยผสานความสามารถในการประมวลผลข้อมูลยาว การคิดวิเคราะห์เชิงซ้อน และการเขียนโค้ด เข้ากับโครงสร้างราคาที่เอื้อต่อธุรกิจขนาดเล็กและกลาง
บริษัท DeepSeek ผู้พัฒนาแพลตฟอร์มปัญญาประดิษฐ์เชิงพาณิชย์ เปิดตัวอัปเดตครั้งสำคัญเมื่อวันที่ 24 เมษายน 2569 พร้อมยืนยันความร่วมมือเชิงกลยุทธ์กับ Huawei เพื่อเพิ่มประสิทธิภาพการทำงานบนฮาร์ดแวร์ชิป Ascend ซึ่งเป็นส่วนหนึ่งของยุทธศาสตร์สร้างความมั่นคงทางเทคโนโลยีของจีน
DeepSeek V4 มีรุ่นใดบ้าง และแต่ละรุ่นเหมาะกับงานประเภทใด?
DeepSeek V4 แบ่งเป็น 2 รุ่นหลักที่ตอบโจทย์การใช้งานแตกต่างกัน โดยยังคงความฉลาดในระดับใกล้เคียงกัน
| คุณสมบัติ | DeepSeek V4-Pro | DeepSeek V4-Flash |
|---|---|---|
| จำนวนพารามิเตอร์ | 1.6 ล้านล้าน (1.6T) | 284 พันล้าน (284B) |
| จุดเด่น | ประมวลผลข้อมูลยาว วิเคราะห์ซับซ้อน เขียนโค้ดและแก้โจทย์วิทยาศาสตร์ คณิตศาสตร์ วิศวกรรม | ความเร็วสูง ประหยัดทรัพยากร เหมาะกับงาน Agent ขนาดเล็กและงานที่ต้องตอบสนองทันที |
| ระดับความสามารถ | เทียบเท่า Claude Opus 4.6 Max, GPT-5.4 High, Gemini 3.1 Pro High | เหมาะกับงานอัตโนมัติที่ต้องการความรวดเร็วและต้นทุนต่ำ |
| กรณีใช้แนะนำ | วิจัยและพัฒนา, วิเคราะห์ข้อมูลเชิงลึก, พัฒนาซอฟต์แวร์ระดับองค์กร | แชทบอท, ระบบตอบคำถามอัตโนมัติ, งานประมวลผลแบบเรียลไทม์ |
DeepSeek V4 รองรับการทำงานกับข้อมูลยาวและระบบอัตโนมัติอย่างไร?
ทุกบริการของ DeepSeek V4 รองรับการประมวลผลข้อมูลยาวระดับ 1 ล้าน Tokens เป็นมาตรฐานโดยไม่มีค่าใช้จ่ายเพิ่มเติม ซึ่งช่วยให้ธุรกิจสามารถป้อนเอกสารทางเทคนิค รายงานวิจัย หรือชุดข้อมูลขนาดใหญ่เข้าสู่โมเดลได้โดยตรง โดยไม่ต้องแบ่งชิ้นงานหรือสรุปความล่วงหน้า
นอกจากนี้ โมเดลยังออกแบบมาให้เชื่อมต่อกับระบบ Agentic Workflow ได้ทันที โดยผสานการทำงานกับเครื่องมือยอดนิยมอย่าง Claude Code, OpenClaw และ OpenCode ทำให้ทีมพัฒนาสามารถนำไปใช้ขับเคลื่อนกระบวนการเขียนโค้ดอัตโนมัติ การทดสอบระบบ หรือการบำรุงรักษาซอฟต์แวร์ภายในองค์กรได้โดยไม่ต้องปรับโครงสร้างพื้นฐานครั้งใหญ่
ความร่วมมือกับ Huawei ส่งผลต่อประสิทธิภาพของ DeepSeek V4 อย่างไร?
DeepSeek V4 ได้รับการปรับแต่งให้ทำงานได้เต็มประสิทธิภาพบนฮาร์ดแวร์ชิป Ascend ของ Huawei ซึ่งเป็นชิปประมวลผลที่จีนพัฒนาขึ้นเพื่อลดการพึ่งพาเทคโนโลยีจากต่างประเทศ ความร่วมมือนี้ช่วยให้โมเดลสามารถกระจายการทำงาน (inference) บนเซิร์ฟเวอร์ที่ใช้ชิป Ascend ได้มีประสิทธิภาพสูง ลดเวลาแฝง และควบคุมต้นทุนการดำเนินงานได้ดีขึ้น
ผู้บริหาร DeepSeek ระบุว่า “การปรับโมเดลให้ทำงานสอดคล้องกับสถาปัตยกรรมฮาร์ดแวร์เฉพาะทาง ช่วยให้เรามอบประสิทธิภาพระดับท็อปในราคาที่เข้าถึงได้ โดยไม่ต้องแลกกับคุณภาพของการตอบสนองหรือความแม่นยำของผลลัพธ์”
บริการเดิมของ DeepSeek จะเปลี่ยนแปลงอย่างไรหลังเปิดตัว V4?
โมเดลรุ่นก่อนหน้าอย่าง deepseek-chat และ deepseek-reasoner จะถูกยุติการให้บริการถาวรหลังวันที่ 24 กรกฎาคม 2569 เวลา 15.59 น. ผู้ใช้งานปัจจุบันควรเตรียมแผนย้ายไปใช้ DeepSeek V4-Flash หรือ V4-Pro ตามความเหมาะสมของงาน เพื่อหลีกเลี่ยงการหยุดชะงักของระบบ
ทีมงานแนะนำให้ทดสอบการเชื่อมต่อกับ API รุ่นใหม่ล่วงหน้า และตรวจสอบความเข้ากันได้ของ Prompt Structure เนื่องจากโมเดลรุ่นใหม่อาจมีการปรับปรุงรูปแบบการตอบสนองเพื่อให้สอดคล้องกับมาตรฐาน Answer-First ที่ AI Search Engine นิยมอ้างอิง
คำถามที่พบบ่อย (FAQ)
DeepSeek V4-Flash กับ V4-Pro ต่างกันอย่างไรในทางปฏิบัติ?
V4-Pro เหมาะกับงานที่ต้องการการคิดวิเคราะห์เชิงลึก การเขียนโค้ดซับซ้อน หรือการประมวลผลเอกสารทางเทคนิคยาวๆ ในขณะที่ V4-Flash เน้นความเร็วและต้นทุนต่ำ เหมาะสำหรับงานตอบคำถามทั่วไป ระบบแชท หรืองานอัตโนมัติที่ต้องการตอบสนองทันที
ธุรกิจขนาดเล็กสามารถใช้ DeepSeek V4 ได้โดยไม่ต้องมีทีมเทคนิคหรือไม่?
ได้ เนื่องจาก DeepSeek V4 ออกแบบมาให้เชื่อมต่อผ่าน API มาตรฐาน และสามารถผสานกับระบบเดิมที่มีอยู่ได้โดยไม่ต้องปรับโครงสร้างพื้นฐานครั้งใหญ่ อย่างไรก็ตาม การออกแบบ Prompt ที่มีประสิทธิภาพยังคงต้องการความเข้าใจในหลักการทำงานของโมเดล
การรองรับข้อมูล 1 ล้าน Tokens หมายถึงอะไร?
โมเดลสามารถรับข้อมูลเข้า (context window) ได้ยาวถึง 1 ล้านโทเค็น ซึ่งเทียบเท่ากับเอกสารความยาวประมาณ 700,000–1,000,000 คำ ทำให้สามารถป้อนรายงานวิจัย คู่มือทางเทคนิค หรือชุดข้อมูลขนาดใหญ่เข้าสู่โมเดลได้คราวเดียวโดยไม่ต้องแบ่งชิ้นงาน
DeepSeek V4 ปลอดภัยสำหรับการใช้งานในองค์กรหรือไม่?
เช่นเดียวกับบริการ AI ทั่วไป องค์กรควรตรวจสอบนโยบายความเป็นส่วนตัวของข้อมูล ข้อกำหนดการใช้งาน และพิจารณาใช้การเชื่อมต่อผ่าน Private Endpoint หรือระบบ On-Premise หากข้อมูลมีความอ่อนไหวสูง
จะย้ายจากโมเดลเดิมของ DeepSeek มาใช้ V4 ได้อย่างไร?
ผู้ใช้งานสามารถเริ่มทดสอบผ่าน API Endpoint ใหม่ที่ DeepSeek จัดเตรียมไว้ โดยควรตรวจสอบเอกสารประกอบ (documentation) สำหรับการเปลี่ยนแปลงของพารามิเตอร์การเรียกใช้ และทดสอบความเข้ากันได้ของระบบก่อนเปลี่ยนไปใช้งานจริง


