OpenAI เคยมีปัญหากับนักแสดงสาว Scarlett Johansson เรื่องการลอกเลียนเสียงมาก่อน และถูกวิจารณ์หนักเรื่อง AI ขัดจังหวะผู้ใช้บ่อยครั้ง OpenAI ปล่อยอัปเดตใหญ่ เมื่อ 4 วันก่อน เปิดตัวโมเดลเสียงรุ่นใหม่ เสียงธรรมชาติ ลื่นไหลเหมือนคุยกับคนจริงๆ แถมแม่นยำกว่าเดิม แต่ไม่ง่าย เพราะคู่แข่งอย่าง Sesame และ Amazon เตรียมพร้อมท้าชน
เปิดตัวโมเดลเสียง
20 มีนาคม 2568 OpenAI เดินหน้าเปิดตัวโมเดลเสียง ที่สามารถปรับแต่งเสียงได้ ให้มีโทนเสียงที่หลากหลาย มีพูดเว้นวรรค แบบไม่พูดแทรก หรือต่อเนื่องกัน เหมือนหุ่นยนต์
โมเดลเสียง 3 รุ่นใหม่
- GPT-4o-Transcribe
- GPT-4o-Mini-Transcribe
- GPT-4o-mini-TTS
ปัญหาหลักของเสียง AI
การขัดจังหวะผู้ใช้บ่อย ในช่วงที่ผู้ใช้เพียงหยุดหายใจ
OpenAI เห็นปัญหานี้ จึงแก้ไขโดยให้ AI รู้จัก “รอ” ให้ผู้ใช้พูดจบก่อนตอบ ช่วยให้บทสนทนาลื่นไหลขึ้น
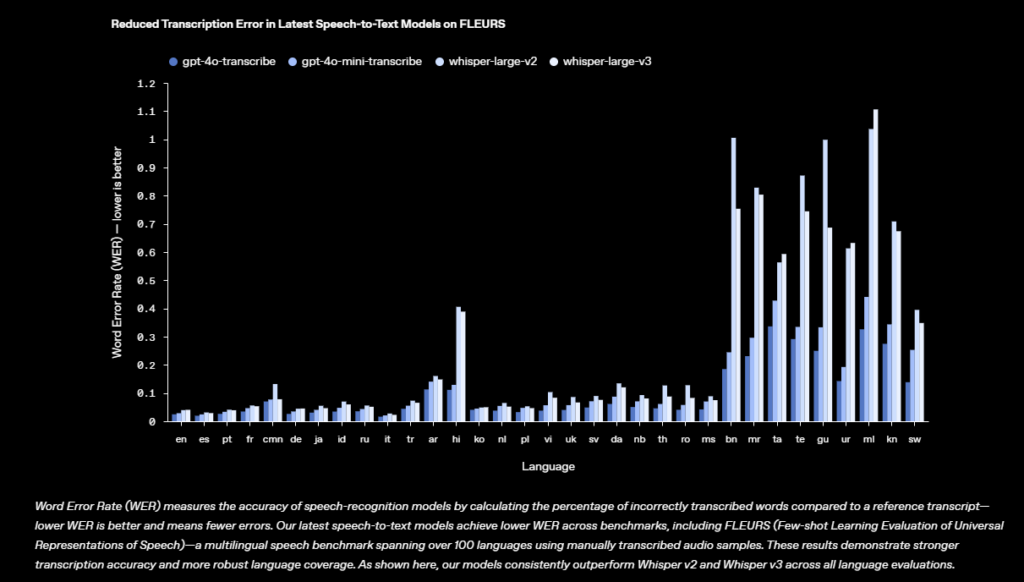
ความสามารถของ GPT-4o-Transcribe , GPT-4o-Mini-Transcribe
– ปรับปรุงอัตราความผิดพลาดของคำ และการรับรู้ภาษาได้ดีขึ้น
– จับความแตกต่างของการพูดได้ดีขึ้น
– ลดการรับรู้คำผิด
– เพิ่มความน่าเชื่อถือของการถอดเสียง
– ปรับปรุงบุคลิกภาพ AI
เสียงใหม่
– ปรับแต่งเสียงได้ตามใจชอบ เปลี่ยนสำเนียง ระดับเสียง อารมณ์ ผ่านคำสั่งข้อความ เช่น ตั้งใจให้พูดเหมือน “นักวิทยาศาสตร์สติเฟื่อง” หรือ “ครูสอนโยคะใจเย็น”
– แม่นยำกว่า Whisper V2-V3 ทำงานดีในสภาพแวดล้อมเสียงรบกวน รองรับ 100+ ภาษา
– เพิ่มฟีเจอร์ Streaming Speech-to-Text การรับข้อความแบบเรียลไทม์ ทำให้บทสนทนาเป็นธรรมชาติ
25 มีนาคม 2568 ปล่อยคลิปวีดิโอ ชาวต่างชาติใช้โมเดลเสียงใหม่ ดูคลิปจาก Shorts ใน Youtube ช่อง OpenAI
โหมดเสียงของ ChatGPT ตอนนี้จะไม่ขัดจังหวะคุณมากเท่าเดิม ทำให้คุณมีเวลาหยุดพักและรวบรวมความคิดได้เต็มที่
จุดเด่นของอัปเดต
ปรับปรุงบุคลิกภาพ AI : ผู้ใช้แบบเสียเงิน (Plus, Teams, Edu, Business, Pro) จะได้รับการตอบกลับที่กระชับ สร้างสรรค์ และตรงประเด็นมากขึ้น พร้อมลดการขัดจังหวะ
ไม่ขัดจังหวะเมื่อผู้ใช้หยุดพูด : ผู้ใช้ฟรีของ ChatGPT จะได้ใช้ Advanced Voice Mode เวอร์ชันใหม่ ที่อนุญาตให้หยุดคิดหรือหายใจได้โดยที่ AI ไม่พูดแทรก
ตัวอย่างการใช้งานจริง
- EliseAI : ใช้โมเดล TTS ทำให้แชทบอทจัดการเช่าอสังหาฯ ได้เป็นธรรมชาติขึ้น ผู้เช่าพึงพอใจมากขึ้น
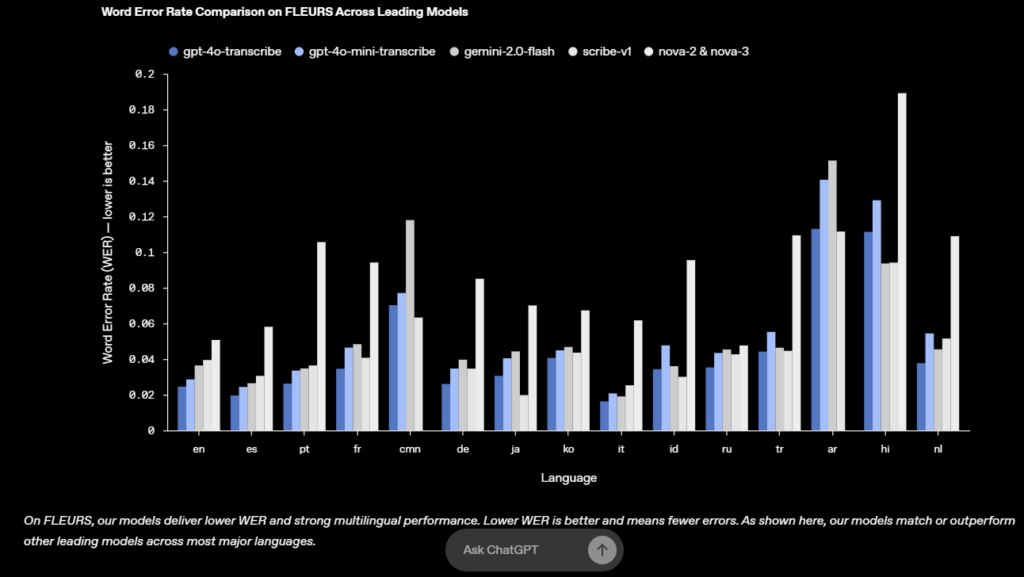
- Decagon : ความแม่นยำการถอดเสียงเพิ่ม 30% แม้ในสภาพแวดล้อมเสียงรบกวน
ราคาและคู่แข่ง
- GPT-4o-Transcribe : 6 ดอลลาร์สหรัฐฯ/1M Tokens (~0.006 ดอลลาร์สหรัฐฯ/นาที)
- GPT-4o-Mini-Transcribe : 3 ดอลลาร์สหรัฐฯ/1M Tokens
- GPT-4o-Mini-TTS : 0.60 ดอลลาร์สหรัฐฯ/1M Tokens ข้อความ + 12 ดอลลาร์สหรัฐฯ/1M Tokens เสียง
ดูเพิ่มเติมจาก: https://platform.openai.com/docs/guides/audio
โมเดลเสียงใหม่พร้อมให้ผู้พัฒนาทุกคนใช้งานแล้ววันนี้
ทดลองเล่น Demo
ผ่าน: https://www.openai.fm/
ตัวอย่างทดลองใช้โมเดลเสียงใหม่
Youtube: https://youtube.com/shorts/mm4djPNO8os
ลองใช้ดูนะครับ แล้วอย่าลืมบอกความคิดเห็นของคุณเข้ามาด้วย! แค่กดไอคอนคลื่นสีดำที่ด้านขวาของกล่องข้อความก็เริ่มได้แล้วครับ
ข้อสรุป:
OpenAI ยกระดับ AI ผู้ช่วยเสียงให้ทำงานได้ใกล้เคียงมนุษย์มากขึ้น ด้วยลดการขัดจังหวะและเพิ่มความแม่นยำ ช่วยให้บทสนทนาลื่นไหลขึ้น ทาง Sesame และ Amazon ต่างพัฒนาเสียง AI แบบก้าวกระโดด ก็มาดูกันว่าใครจะครองความเป็นผู้นำในระยะยาว