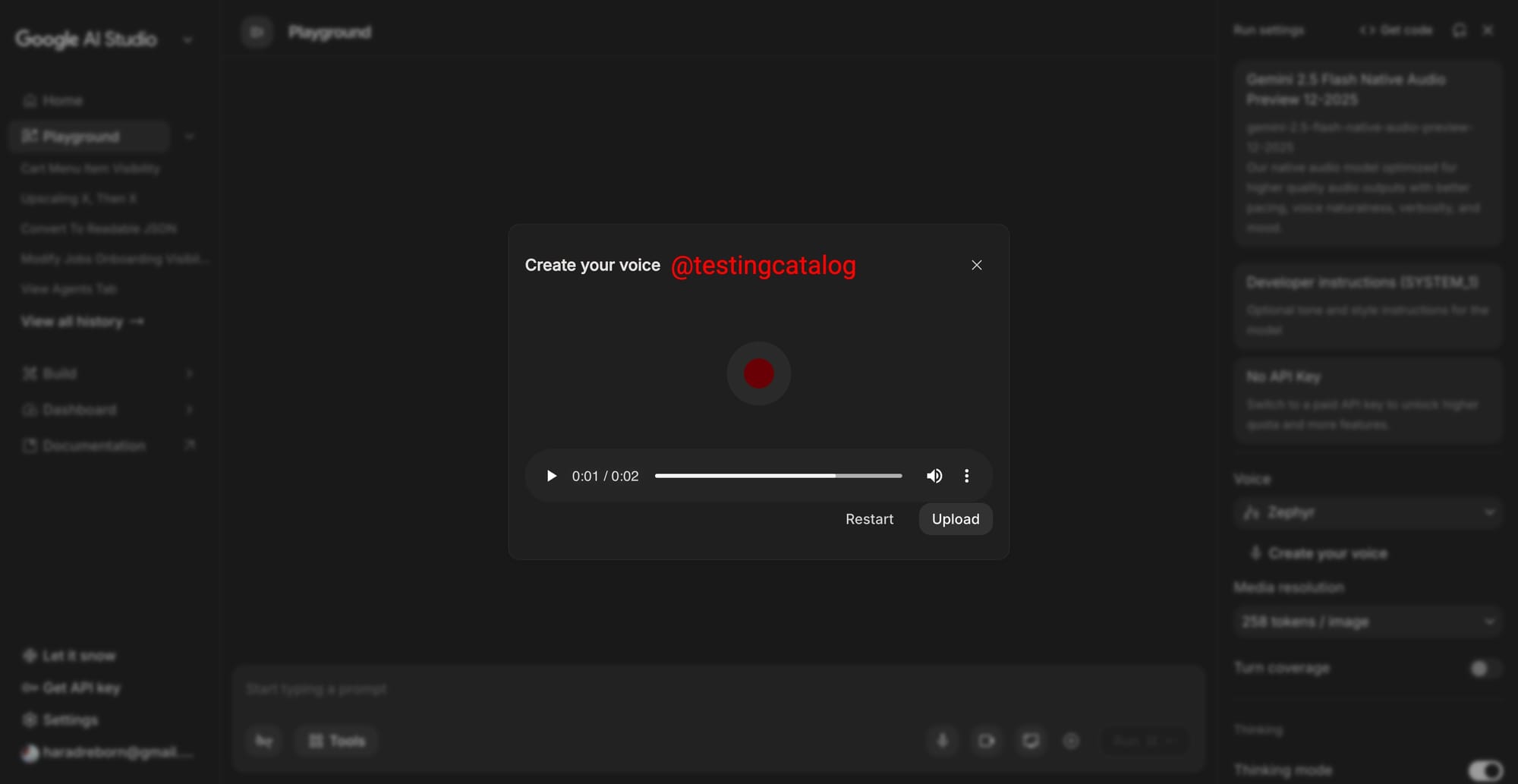
Google เหมือนกำลังลองของเงียบ ๆ ใน Google AI Studio มีคนไปเจอเมนูที่ซ่อนไว้ชื่อ Create Your Voice โผล่มาตอนเลือก Flash Native Audio Preview (ที่ตอนนี้ยังอยู่กับ Gemini 2.5 Flash)
28 มกราคม 2569 Google น่าจะกำลังปูทางไปสู่การปล่อย Native Audio Model ที่เก่งขึ้น (มีโอกาสเป็น Gemini 3 Flash) และอาจปล่อย Voice Cloning มาพร้อมกัน หากเปิดใช้จริง นักพัฒนาจะสามารถสร้างเสียงสังเคราะห์ จากตัวอย่างเสียงที่ผู้ใช้ให้มาได้ ทำให้เสียงตอบกลับของ AI มีความเป็นส่วนตัวมากขึ้น
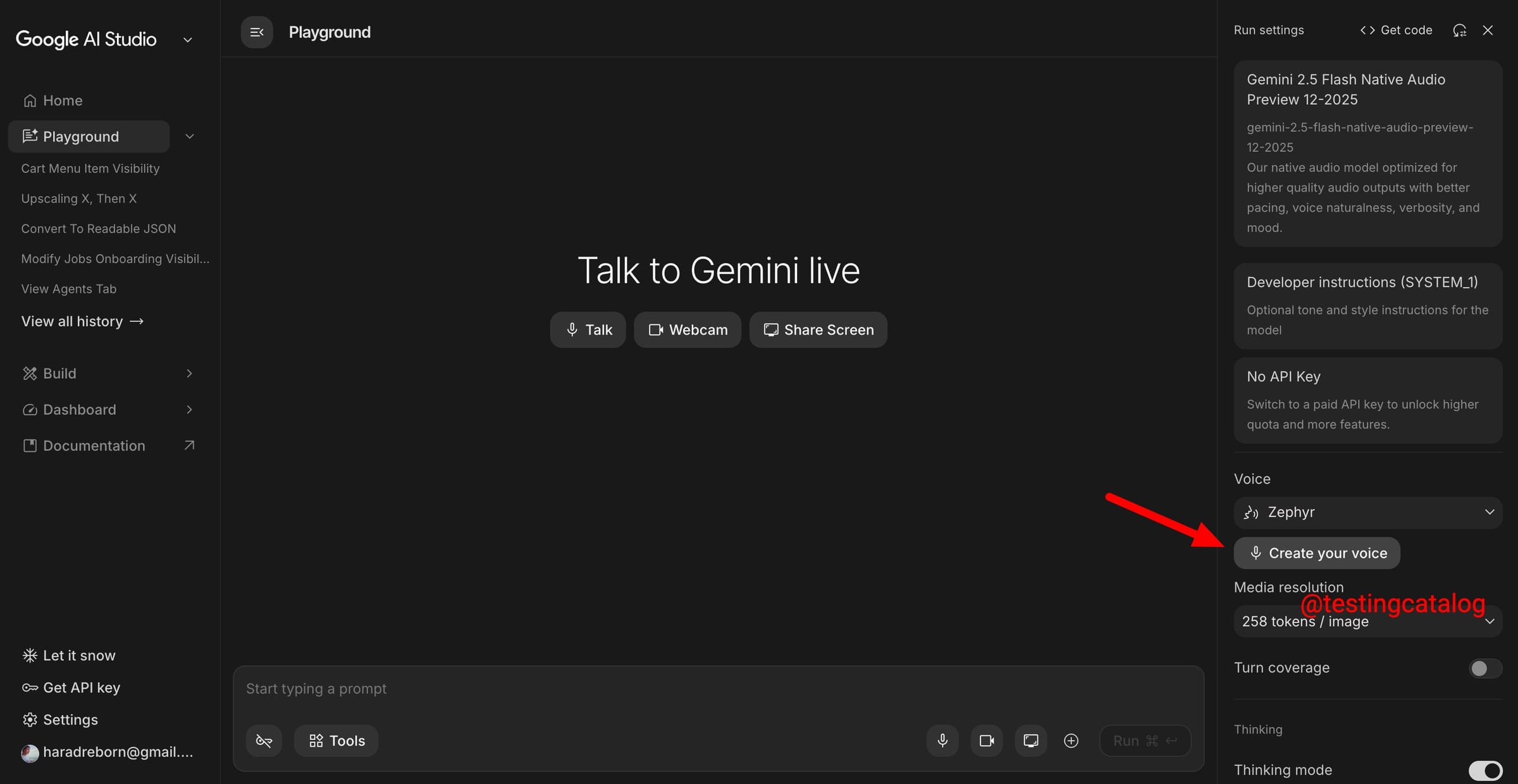
เพียงกดเข้าไปแล้วจะมีหน้าต่างให้ อัดเสียง และ อัปโหลดไฟล์เสียงได้ แต่ฟีเจอร์ยังใช้งานจริงไม่ได้ เหมือนอยู่ช่วงทดสอบ/เตรียมระบบ ใน Google, Voice Cloning มีที่อื่นทำได้อยู่แล้ว แต่ถ้ามันฝังมาใน Gemini + AI Studio ก็จะช่วยลดขั้นตอนยุ่งยากสำหรับคนที่ทำงานอยู่ใน Ecosystem ของ Google เป็นหลัก
การเพิ่ม Voice Cloning ลงใน Google AI Studio ส่งผลอย่างไร
- Personalization จะขยับจาก ข้อความ เป็น เสียง
- แอปที่ชนะในยุคต่อไป ไม่ใช่แค่ตอบเก่ง แต่ต้องพูดเป็นเสียงที่คนอยากฟัง เช่น เสียงแบรนด์, เสียงผู้ใช้, หรือเสียงมาตรฐานขององค์กร
- Workflow ของนักพัฒนาจะสั้นลงมาก
- ถ้า Voice Cloning อยู่ใน AI Studio เลย = อัปโหลดเสียง → เลือกโมเดล → ทดลองเสียงตอบกลับได้ทันที Dev ไม่ต้องวิ่งหลายเครื่องมือให้เสียเวลา
- สัญญาณว่า AI Studio กำลังเป็นแพลตฟอร์มทำโปรดักต์จริง
- นอกจากเรื่องเสียง ยังมีข่าวว่ากำลังเพิ่ม Import from GitHub แปลว่า Google อยากให้ AI Studio เป็นที่ที่เอาโค้ดเข้ามาแล้วทำต่อได้เลย ไม่ใช่แค่หน้าเล่นเดโม
ข้อสรุป:
Google อยากให้ AI Studio เป็นเครื่องมือที่มีของครบสำหรับคนสร้างแอป AI ทำให้ทุกอย่างอยู่ในที่เดียว ตั้งแต่ลองโมเดลจัดการ โปรเจกต์ จนถึงเชื่อมโค้ดจาก GitHub ทีมธุรกิจเลยปล่อยของได้ไวขึ้นและทำประสบการณ์ลูกค้าให้ต่างจากคู่แข่งได้ชัดกว่าเดิม