AI ที่มีประสิทธิภาพสูง มักกินทรัพยากรและค่าใช้จ่ายสูง ไม่เหมาะกับงานที่มีจำนวนมาก Gemini 2.5 Flash-Lite เปิดตัว เร็วขึ้น 1.5x ประหยัดกว่า พร้อมประสิทธิภาพใหม่เพียบ
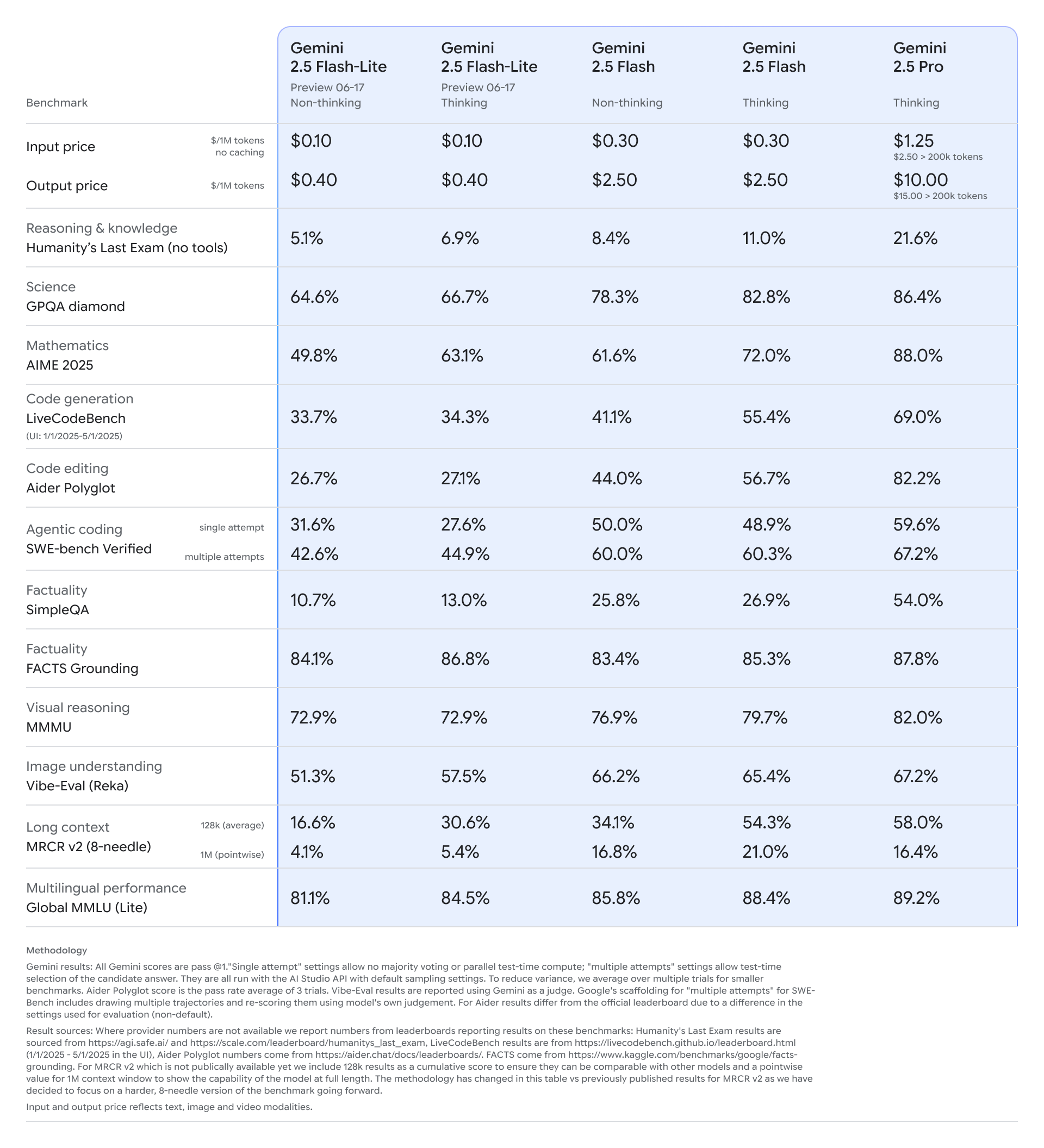
17 มิถุนายน 2568 Google ได้เปิดตัว Gemini 2.5 Flash-Lite มีเป้าหมายเพื่อให้ผู้ใช้งานสามารถทำ tasks จำนวนมหาศาลได้อย่างรวดเร็วและประหยัด ด้วยความล่าช้าต่ำ
ทำไมถึงน่าสนใจ?
– ลดต้นทุนเมื่อเทียบกับโมเดลรุ่นก่อน แต่ยังคงคุณภาพในการประมวลผล
– พิสูจน์แล้วว่าทรงพลังจริงในงาน Enterprise
ฟีเจอร์
- เร็วกว่า Gemini 2.0 Flash ถึง 1.5 เท่า
- งานที่ต้องทำจำนวนมากและทำเสร็จไว เช่น การจำแนกประเภท, การแปล, การประมวลผลข้อความขนาดใหญ่
- ทำงานได้ดีในสภาพแวดล้อมที่ต้องการ Low Latency
มีความสามารถพื้นฐานจากตระกูล Gemini 2.5 เช่น การตอบคำถามเชิงตรรกะ, การเขียนโค้ดพื้นฐาน, การเข้าใจข้อมูลหลายรูปแบบ (Multimodal)
ประโยชน์ที่ได้
- ปรับใช้ในระบบงานประจำวันได้จริง เช่น ระบบแปลอัตโนมัติ, Chatbot สำหรับตอบคำถามทั่วไป
- เพิ่มประสิทธิภาพการบริการลูกค้าโดยไม่เปลืองงบ
- ลดเวลาในการพัฒนาโมเดล เพราะเริ่มต้นจากโมเดลที่ฝึกมาแล้ว
ราคาและการใช้งาน
- อยู่ในช่วง Public Preview บน Vertex AI
- ราคาในช่วง Preview ถูกออกแบบมาเพื่อสนับสนุนการทดลองใช้จริง
- ใช้ผ่าน Google AI Studio และ Vertex AI ได้เลย
ข้อสรุป:
Gemini 2.5 Flash-Lite ทางเลือกใหม่สำหรับองค์กรที่ต้องการทำ AI ในปริมาณมาก ด้วยต้นทุนที่ควบคุมได้ และทำได้เร็วกว่าเดิมจริง