เวลาคนใช้งานมือถือ/เว็บจริง ๆ เราไม่ได้พิมพ์ เป้าหมายออกมาตรง ๆ เราทิ้งร่องรอยไว้ผ่านการแตะ เลื่อน พิมพ์ เปิดหน้าใหม่… แล้วค่อย ๆ ไปถึงสิ่งที่ต้องการ
ปัญหา คือ ถ้าจะให้ AI ช่วยแบบผู้ช่วยจริง มันต้องเดาให้ถูกว่า เรากำลังทำอะไรอยู่ แต่โมเดลใหญ่ ๆ ที่ทำได้ดี มักต้องส่งข้อมูลขึ้นเซิร์ฟเวอร์ → ช้า แพง และเสี่ยงเรื่องข้อมูลส่วนตัว
ปี 2025 Google Research เผยแพร่งานวิจัย Small Models, Big Results: Achieving Superior Intent Extraction Through Decomposition
Framework แทนที่จะให้โมเดลเล็กเดาทุกอย่างทีเดียว… เขา แยกงานออกเป็น 2 Stages (decomposition)
2 ด่านที่ทำให้โมเดลเล็กเก่งขึ้นแบบใช้งานจริง
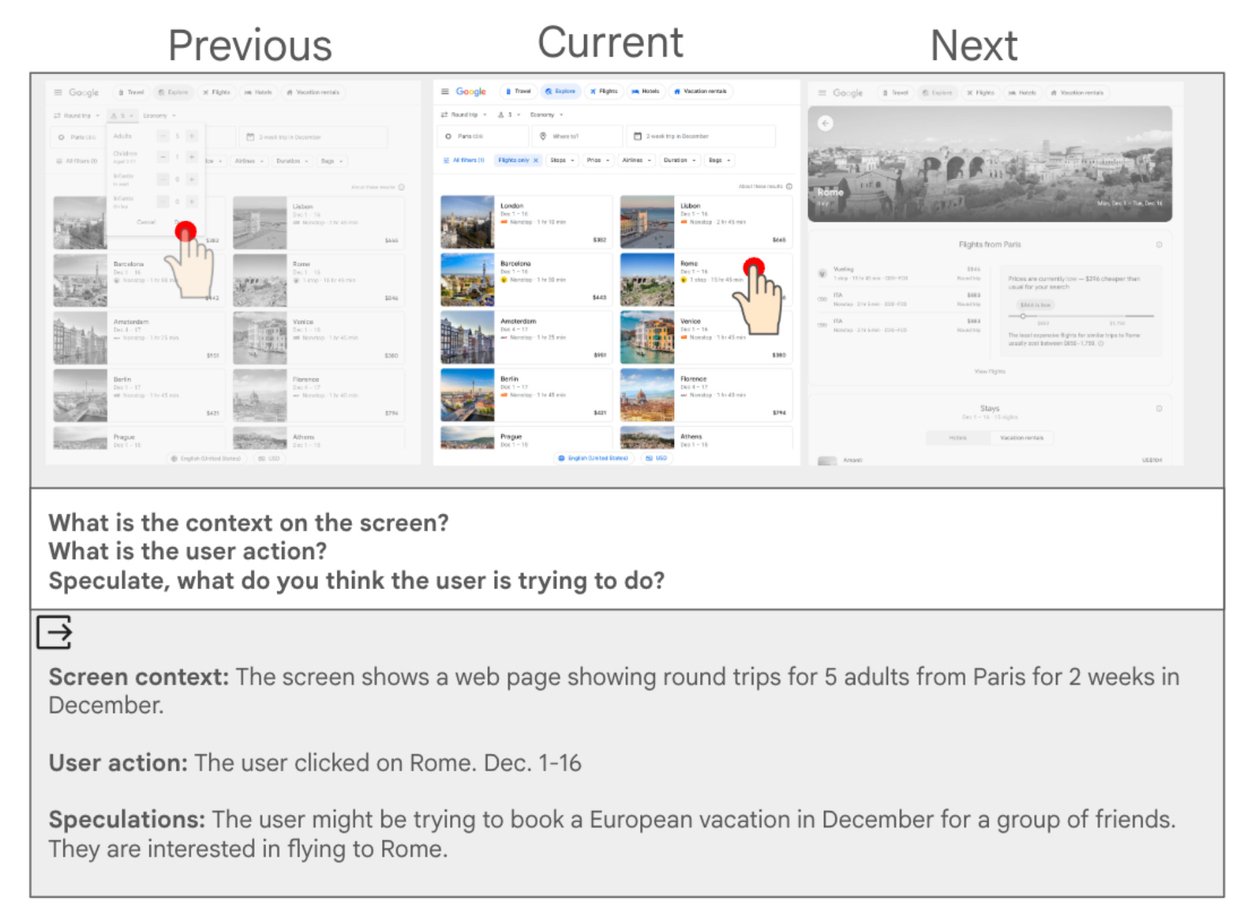
- Stage 1: สรุปทีละหน้าจอ (Screen Summary)
- ดูหน้าก่อน-หน้าปัจจุบัน-หน้าถัดไป แล้วตอบ 3 เรื่องสั้น ๆ
- หน้านี้มีบริบทสำคัญอะไร
- ผู้ใช้เพิ่งทำ action อะไร
- มีการ Speculate ในขั้นนี้ เพื่อให้สรุปครบ
- ดูหน้าก่อน-หน้าปัจจุบัน-หน้าถัดไป แล้วตอบ 3 เรื่องสั้น ๆ
- Stage 2: ดึง Intent จากชุดสรุป (intent extraction)
- เอาสรุปหลาย ๆ หน้ามาเรียงเป็นเหตุการณ์ แล้วให้โมเดลเล็กที่ถูกปรับแต่งแล้ว สรุป Intent ออกมาเป็น ประโยคเดียว และที่เด็ด คือ ตัด Speculations ทิ้งตอนดึง Intent เพื่อลดความสับสน/ลดการหลุด
Framework นี้ เอาไปทำอะไรได้บ้าง
- ทำผู้ช่วยในแอปให้เข้าใจสิ่งที่ผู้ใช้กำลังทำ แล้วเสนอ Next Action แบบพอดี ๆ
- ลดการส่งข้อมูลขึ้นคลาวด์ในงานที่ Sensitive (เช่น พฤติกรรมการใช้งาน/ข้อมูลส่วนตัวบนหน้าจอ)
- ออกแบบระบบ Assistant ที่คุมต้นทุนได้ดีขึ้น โดยไม่ต้องพึ่งโมเดลใหญ่ทุกจุด
ข้อสรุป:
Small models, big results คือ AI ที่ช่วยงานบนมือถือ/เว็บแบบ ฉลาดขึ้น บางทีคำตอบไม่ใช่ หาโมเดลที่ใหญ่กว่า แต่อาจเป็นแตกงานให้ถูก Steps แล้วให้โมเดลเล็กทำในสิ่งที่มันทำได้ดีที่สุด