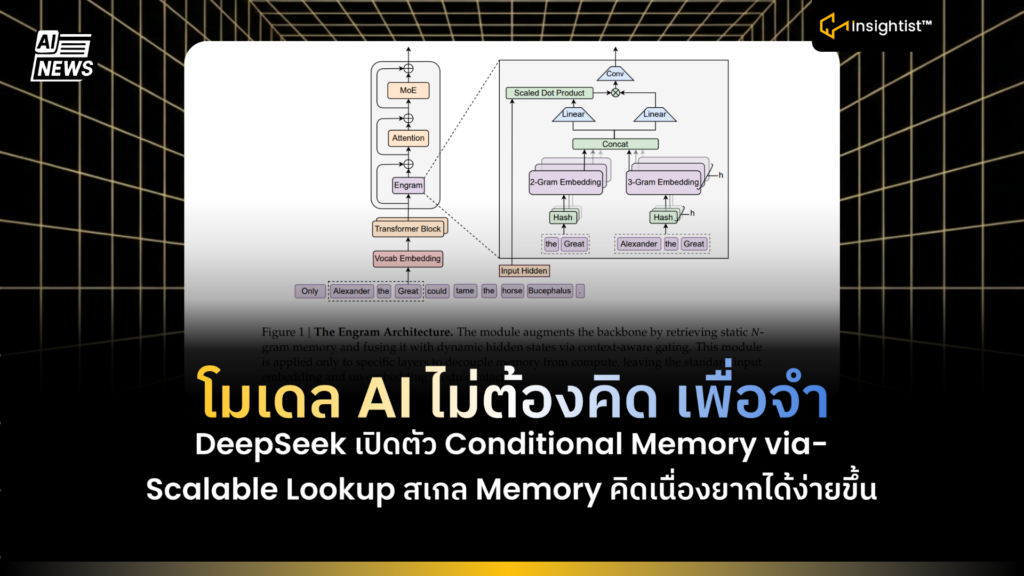
เคยรู้สึกไหมว่า…บางที AI ตอบช้า ไม่ใช่ เพราะมันไม่เก่ง แต่เพราะมันต้อง คิดวน เพื่อหาเรื่องที่ควรหยิบจากความจำได้เลยงานวิจัยนี้เสนอไอเดียตรง ๆ ว่า โมเดลภาษาไม่ควรใช้พลังไปกับการคิด เพื่อจำ ตลอดเวลา
สิ่งที่เขาเพิ่มเข้าไป คือ Conditional Memory คือ ความจำที่เรียกใช้เฉพาะตอนจำเป็น ผ่านโมดูลชื่อ Engram ที่ทำ Scalable Lookup แบบเร็วมาก (ระดับ O(1))
12 มกราคม 2569 DeepSeek เปิดตัว Conditional Memory via Scalable Lookup
มันช่วยอะไรจริงในมุมธุรกิจ?
- ตอบเร็วขึ้นแบบมีเหตุผล
- บางคำ/บางแพทเทิร์นเป็นของเดิม ๆ ที่เจอบ่อย เช่น ชื่อองค์กร, สำนวน, รูปแบบประโยค Engram ช่วยหยิบให้เลย แทนที่จะให้โมเดลคำนวณวนทุกครั้ง
- คิดเรื่องยากได้มากขึ้น
- เมื่อโมเดลไม่ต้องเสียแรงกับของซ้ำ ๆ Compute จะถูกเหลือไว้ให้กับงานที่ต้องคิดตามบริบทจริง ๆ ทำให้คะแนนด้าน reasoning และ math/code ดีขึ้นตามรายงานของงานนี้
- งานยาว ๆ เสถียรขึ้น (long-context)
- ภาระ local pattern ถูกย้ายไปให้ memory attention มีแรงไปจัดการภาพใหญ่ของบทสนทนาหรือเอกสารยาว ๆ ได้มากขึ้น
- สเกลได้แบบคนทำระบบชอบ
- จุดที่โหด คือ lookup เป็น deterministic เลยทำ prefetch ได้ และสามารถ offload memory ไป host memory ได้ง่ายขึ้น แปลว่า เพิ่มความจำ โดยไม่ต้องยัดทุกอย่างไว้บน GPU ตลอดเวลา
Framework ทำงานยังไง
- ลองนึกว่า LLM ปกติเป็นคนที่ต้องนั่งคิดทุกอย่างเอง แต่ Framework นี้เพิ่มสมุดโน้ตความจำ ที่เปิดหาได้ไวมาก ๆ เวลาเจออะไรที่เป็นของเดิม ๆ ซ้ำ ๆ ก็ไม่ต้องคิดวน ให้เปิดสมุด แล้วหยิบมาใช้เลย
ขั้นตอนการทำงาน
- รับข้อความเข้ามา
- โมเดลรับคำ/ประโยคเข้ามาตามปกติระหว่างที่กำลังจะคาดเดาคำถัดไป ระบบจะเช็กว่า…
- มีอะไรที่ควร “หยิบจากความจำ” แทนการคิดยาวไหม
- ทำให้คำ อยู่ในรูปมาตรฐาน ก่อน (Tokenizer Compression / Vocabulary Projection)
- บางคำหน้าตาเหมือนกัน แต่ในระบบมันอาจถูกนับเป็นคนละแบบ เช่น ตัวพิมพ์ใหญ่-เล็ก, รูปแบบเขียนต่างกันนิดเดียว
- Framework เลยจัดระเบียบคำ ก่อน ให้ของที่ควรเป็นเรื่องเดียวกัน
- ถูกมองเป็นเรื่องเดียวกัน → เพื่อให้ความจำไม่เปลือง และหาเจอง่ายขึ้น
- สร้างแพทเทิร์นสั้น ๆ จากคำแถว ๆ นั้น (N-gram)
- จากคำที่อยู่ติด ๆ กัน ระบบจะหยิบเป็นชุดสั้น ๆ เช่น 2 คำ / 3 คำ เพื่อจับ แพทเทิร์นที่เจอบ่อย ได้เร็วขึ้น มันดูว่า ตรงนี้เป็นวลี/รูปแบบที่คุ้นไหม ไม่ได้อ่านทั้งย่อหน้า
- แปลงแพทเทิร์นเป็น กุญแจ แล้วเปิดหา (Hashed lookup → Scalable Lookup)
- พอได้แพทเทิร์นแล้ว ระบบจะทำเป็นกุญแจ ด้วย hash แล้วเอากุญแจนี้ไปเปิดตารางความจำของ Engram
- จุดสำคัญ คือ การเปิดหาแบบนี้ไวมาก และตรงไปตรงมา (ประมาณ O(1))
- ได้ memory กลับมาเป็นชิ้น ๆ แล้วรวมเป็นก้อนเดียว
- Engram อาจหยิบได้หลายชิ้นจากหลายแพทเทิร์น สุดท้ายระบบจะรวมให้กลายเป็น memory vector ก้อนเดียว เพื่อพร้อมเอาไปช่วยโมเดลในขั้นถัดไป
- มีตัวคุมว่า ควรเชื่อความจำแค่ไหน (Context-aware Gating)
- นี่คือชิ้นที่ทำให้มันไม่มั่ว:
- ถ้าบริบทตอนนี้ “เข้าทาง” และแพทเทิร์นชัด → เปิดใช้ memory มากขึ้น
- ถ้าบริบทไม่ชัด หรือเสี่ยงหลุดประเด็น → ลดการใช้ memory ลง
- Memory ไม่ได้มาบังคับ เป็นเหมือนตัวช่วยที่เปิด-ปิดตามสถานการณ์
- เอา memory ที่ได้ ไปผสมเข้ากับการคิดของโมเดล
- พอได้ memory + ผ่าน gating แล้ว ระบบจะเอาไปผสมกับ hidden state ของโมเดลในบาง layers (ไม่จำเป็นต้องใส่ทุกชั้น)
- ผลที่ได้คือ
- ของเดิม ๆ ที่ควรจำได้ → หยิบมาใช้ไว
- Compute ถูกเก็บไว้ให้คิดเรื่องยาก/คิดตามบริบท มากขึ้น
โมเดลที่เก่งขึ้น อาจมาจากการจัดสรร คิด vs จำ ให้ถูกที่ถูกทาง ไม่ใช่แค่เพิ่มพลังคำนวณอย่างเดียว
AI รุ่นถัดไป อาจไม่ได้แข่งกันแค่ ใครใหญ่กว่า แต่แข่งกันที่
ใครแบ่งงานได้ฉลาดกว่า
- งานที่ต้อง คิด → ให้ MoE / compute จัดการ
- งานที่ต้อง จำ/หยิบใช้เร็ว → ให้ Engram / memory lookup ดูแล
ข้อสรุป:
โมเดลนี้ คือ มีความจำแบบเปิดหาไว เวลาเจอของเดิม ๆ ซ้ำ ๆ ก็หยิบมาใช้เลย ไม่ต้องนั่งคิดวนให้เสียแรง ตอบคมขึ้น และรับมือข้อความยาว ๆ ได้เสถียรกว่าเดิม เอาไปใช้กับงานกับระบบถามตอบในองค์กร แชตช่วยงานลูกค้า และงานที่ต้องคุยยาวหรือค้นข้อมูลให้เร็วขึ้น, คุมต้นทุนได้ดีขึ้น



