


ปัญหาเดิมของ AI ทำวิจัย คือ ดูเหมือนเก่ง แต่เชื่อได้แค่ไหนไม่มีใครบอกชัด ๆ บางทีตอบถูก 1-2 จุด แต่พอเอาไปใช้จริงกลับเจอว่า ข้อมูลไม่ครบ / อ้างอิงไม่แน่น / วิเคราะห์ลำเอียงโดยไม่รู้ตัว
4 กุมภาพันธ์ 2569 Perplexity เปิดตัว Draco (Deep Research Accuracy, Completeness, and Objectivity) เป็น Open Benchmark ประเมิน Deep Research Agents ยึดจาก วิธีที่คนใช้ AI จริง ๆ เวลาต้องทำงานวิจัยที่ซับซ้อน ไม่ใช่วัดแค่ว่า ตอบได้ แต่ต้องวัดว่า ตอบแล้วเอาไปใช้ได้จริงไหม
มี 100 tasks ครอบคลุม 10 domains และแต่ละ task มีเกณฑ์ตรวจเฉลี่ย ~40 ข้อ เน้นหนักที่ Factual Accuracy, ความครบถ้วน, ความเป็นกลาง และคุณภาพการอ้างอิง
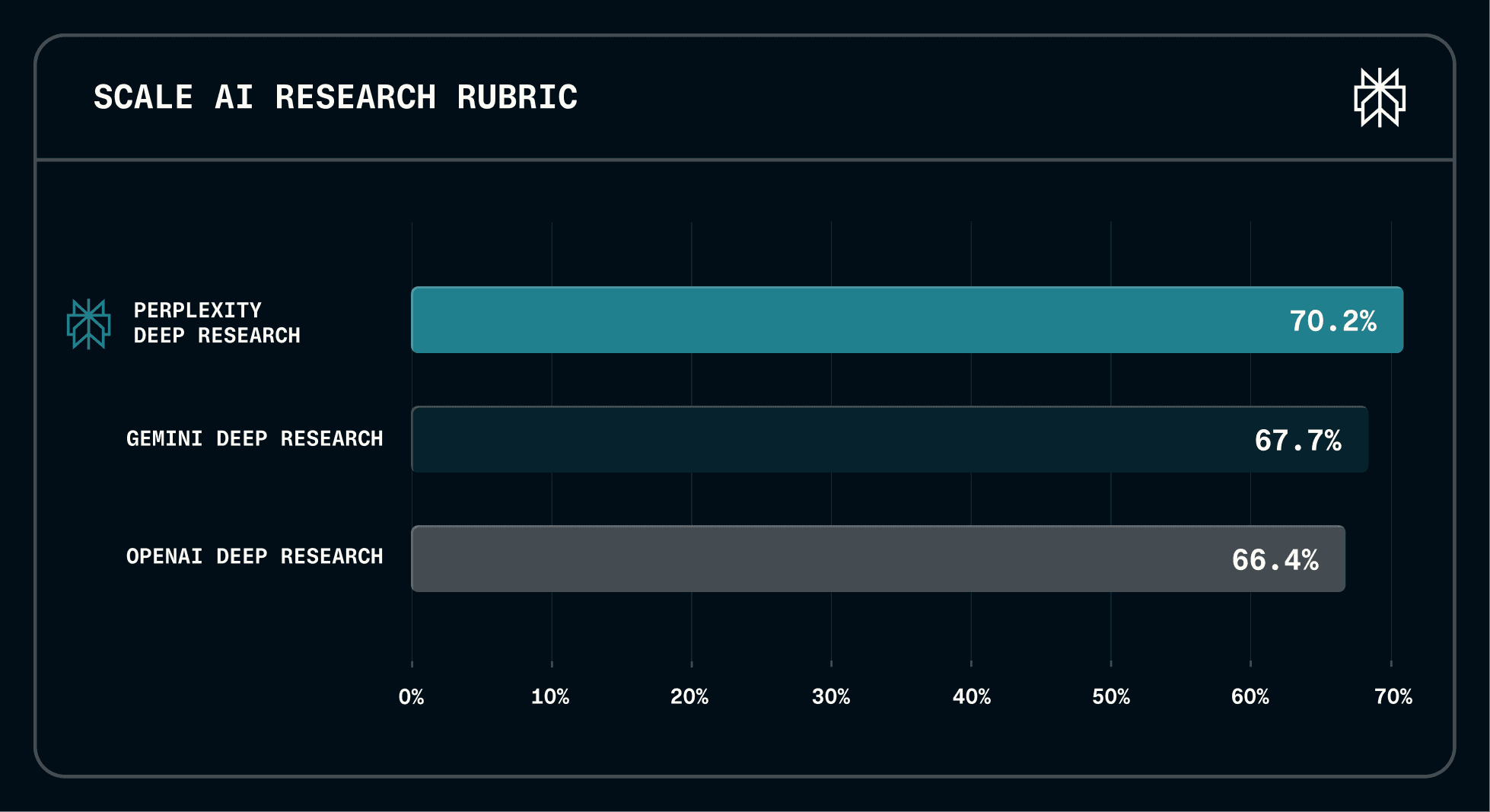
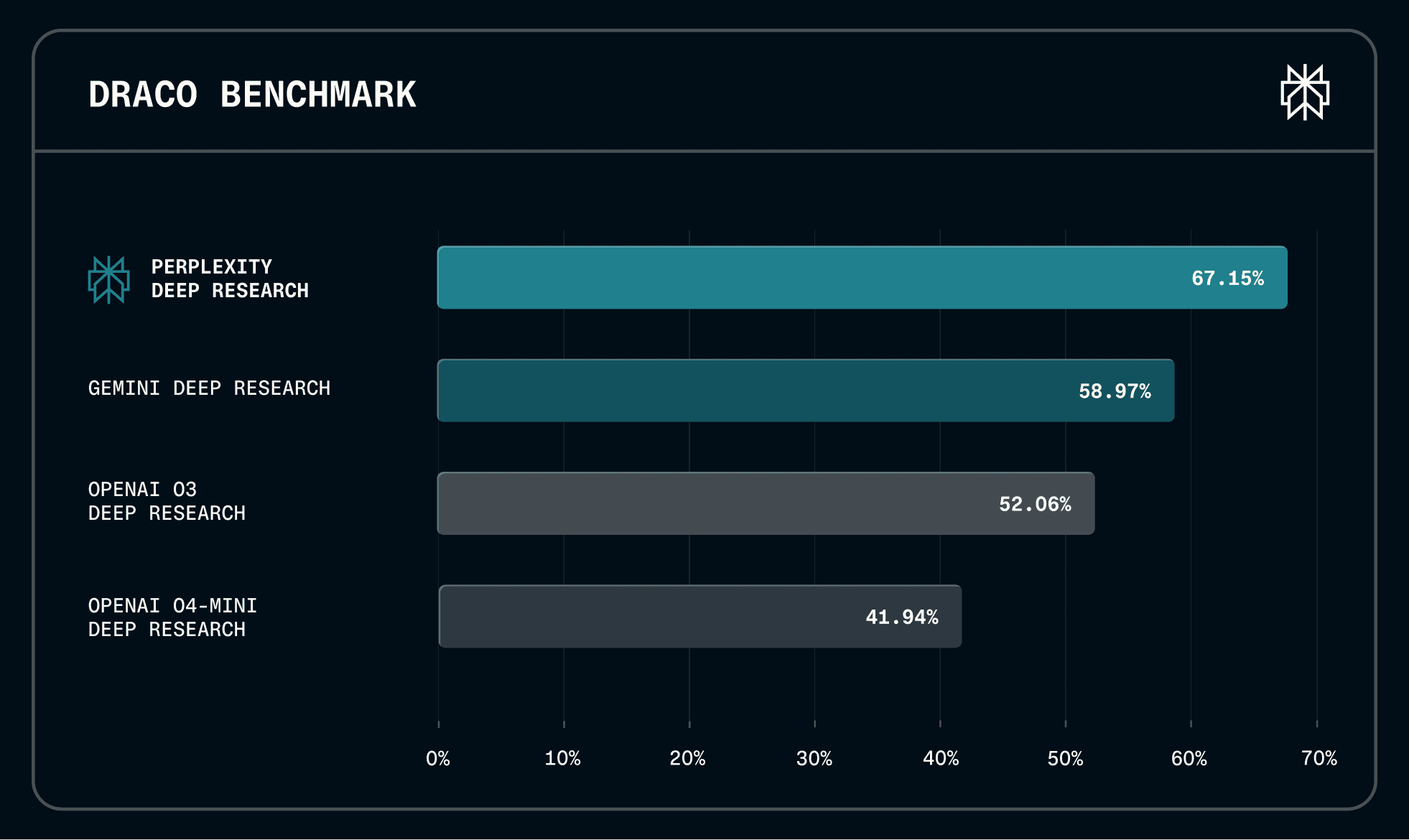
Draco เอาไปทำอะไรได้ทันที
- ทีม Data/AI ใช้เทสต์โมเดล/Agent ก่อนปล่อยใช้จริง
- ผู้บริหารใช้เป็นกรอบคุยกับทีม: เราจะวัดความน่าเชื่อถือของ AI ยังไง
- องค์กรใช้เป็นมาตรฐานกลางเวลาเทียบ vendor หรือเทียบ tool
ข้อสรุป:
DRACO คือ มาตรวัดที่ทำให้ AI ทำวิจัยจากของเล่น → เครื่องมือทำงานจริงได้แบบปลอดภัยขึ้น


